Equally distributing uploaded files with md5 hashing of timestamp
Lately I have been digging into django source code to find out how to get access to actual file field for renaming during upload in general case. This turned out to be impossible because this information is lost as django passes whole instance to upload_to instead of file field itself. There was a need to do some magic during file upload based on the actual file content hash. But during the exploration I found that for a long time I have been using two level depth folder structure to limit amount of files stored per folder. It looked a bit reduntant for my usecases and led me to exploration of how should I split the files into folders.
So let’s say we have some model which stores an ImageField in it with upload_to set to some function that generates path.
class Item(models.Model):
name = models.CharField(max_length=256)
description = models.TextField()
image = models.ImageField(upload_to=item_image_path_gen, null=True)
In the item_image_path_gen function we the Item instance and name of the file that was passed. The name can be anything and I prefer to normalize it something. Without trying to be fancy I usually just use an md5 on the file contents. It is not required but there were some projects where using this approach helped finding ‘missing’ files faster.
So let’s say that user passed us file ‘Photo 000323(3) .jpg’. Of course we don’t whant to store it directly with this name in our system. First of all it could be a privacy issue as the name can give out too much information and second we don’t want to have any space or some random characters which might or might not be supported by current file system.
Let’s assume that this photo is md5 hashed into ffbafafd06f9245e76b5dce27479d504 we append whatever is the file extension to get ffbafafd06f9245e76b5dce27479d504.png. For a two level depth folder structure we take first [:a] and [a:b] characters and put the image/file into respective folders.

Why not put everything into one folder? Well there are variaty of reasons starting from different file systems not liking it and all the way to slow opening and listing in some other cases. Depending on the circumstances I could try to keep it under 1k but even 4k seems not that bad.
So once I stumbled upon 3 chars per folder split in one of my projects I thought that it should be that it could be too much splitting into folders but is it? Let’s try to calculate. The plan is for the system to be handle several million files with upper limit of 100 million files (with average of 10kb per file).
If you used only decimals in our file name with folder depth of 2 then we would have 100_000_000 files / (999999 folders) = 100.2 files per folder. If we use hex numbers (as in example md5) for the file name then 3 chars make it 161616 = 4094 folders per level or total of 40964096=16777216 total possible folders to store files or just about 6 files per folder. Even if we had a had just 1k files per folder we are still very very under budgeted.
But had an issue of django not passing file field and instead giving us just instance. The issue with this is that we totally lose any information about what we are working on. Very strange decision by django team as if they just passed the field itself, if we needed instance, we could have gotten it out of the field with just on lookup. Anyways we are not trying to solve parameter passing issue but rather solve our current problem. The problem is that I have a lot of models with different file and image fields in it and wanted to have single function handling all the naming work.
Possible solution is to use file name as hash parameter. It is not suitable as passed files could have the same name which will will skew our distribution and creates uncertainty which we tried reduce. We could pass the field name to the function and get out file contents with that. But it makes our code fragile and prone to human input error which is also undesirable.
The approach I wanted to try is to use time as hash function input and calculated file names out of that. This sound as a good idea but how good is md5 output distribution. I am not a professional matematician or cryptographer and could not trust my theoretical reasoning about it but I could write small simulations and get approximate result emperically. This is good enough for my usecase. So I did it.
For this I used regular python datetime module’s now() method and then get hash value of stringified timestamp:
current_time = datetime.datetime.now().timestamp()
calculated_hash = hashlib.md5(str(current_time).encode('utf-8')).hexdigest()
Then I just calculated hash value 100 million times successively for each reported timestamp. All timestamp values will be very close and should show anomalies if there is any.
Here is folder distribution:

First let’s see how the the number of folders got distributed in our second level as our first level got completely saturated. So on the first level we fully used all our 4k space (for 3 char hex). One the second level we also came close to fully filling all our available folder space. The full amount of second depth folder count per first level folder is 4096 and in the graph we the that all values are balancing around max value.
Let’s look at file distribution:
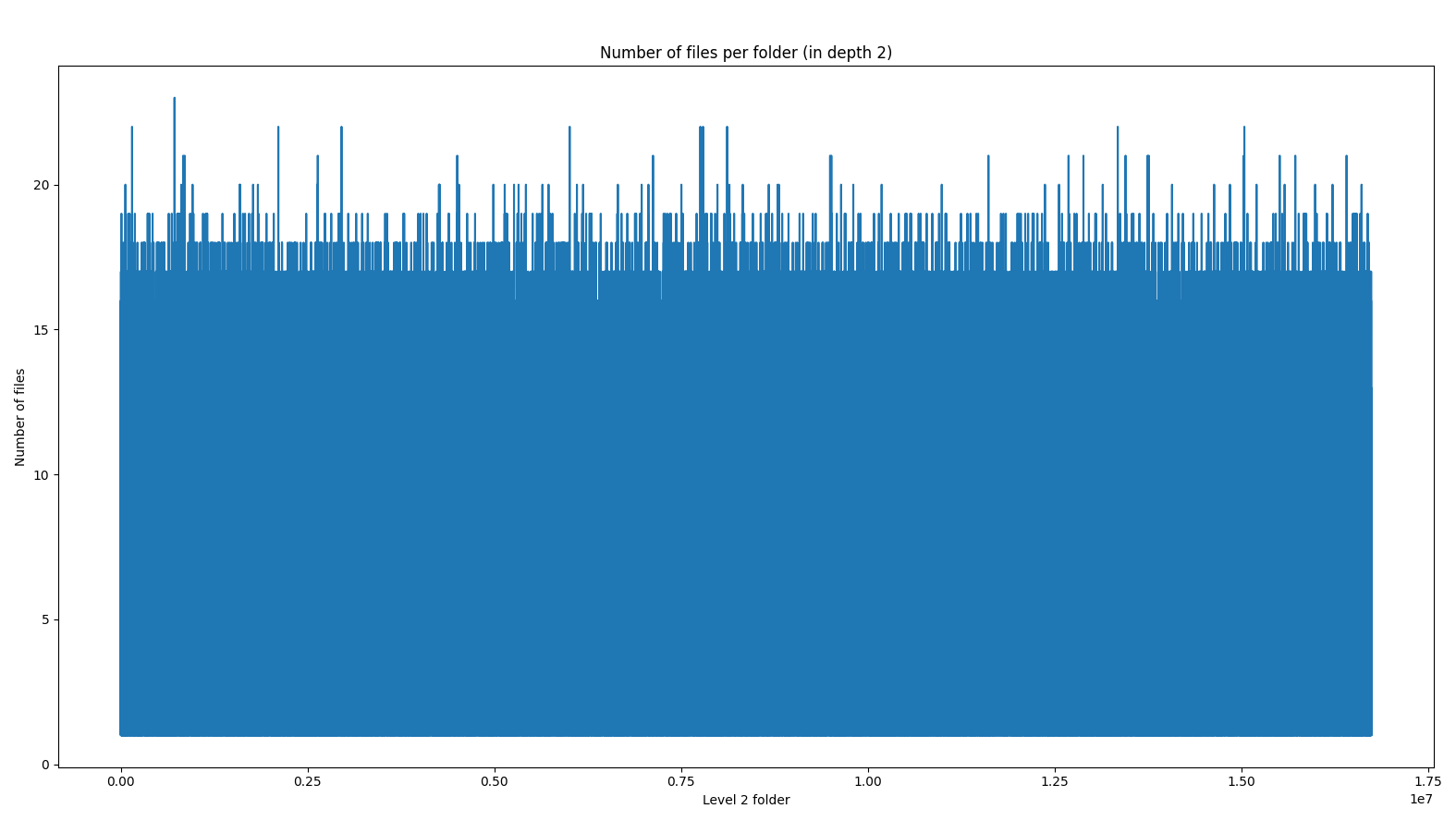
Strange. From th first glance on the graph it looks likes each folder has more that 16 files. But in our initial calculations we got about 5 files per folder. So either md5 is not distributing our files evenly or we miscalculated. If we look on the X axis we see that there are more than 16 million folders or 16_733_900 to be exact. If we have 16-17 files per folder then there are around 300 million files and that is not correct. The issue is that on X axis we have 16 million values and drawing that many lines just don’t show correct information about true distribution.
Diffent slicing of the data (looks like skewed normal distribution):
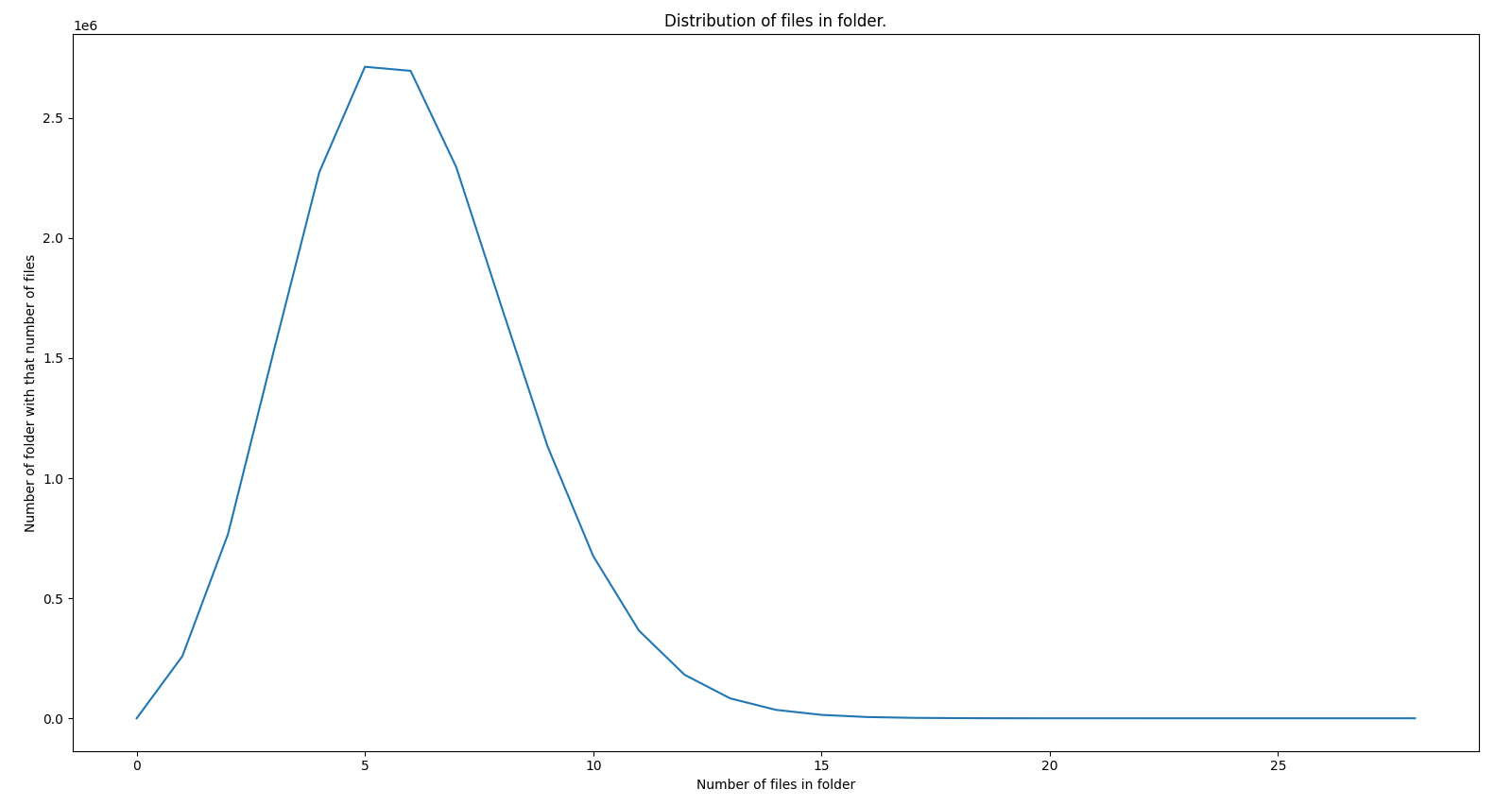
In this graph on the X axis we show number of files per folder and on Y axis we show number of folder with that many files in it. Here we can see that amount of folder that have about 5 files is the largest group. Issue with the previous graph was that there are 14000 folder containing 15 files, 5000 folders containing 16 fiels, … , 40 folders containing 20 files. Even though on this graph this numbers are almost zero an looks like do not contribute to the overal distribution, on previous graph they had lines attributed to them and with that many lines drawn we can’t see the picture.
So it looks md5 is good enough for the usecase of file distribution. But store on average 5 files per folder seems very wasteful. To store 100 million files we created 16 million folders. So let’s try the same thing but with different prefix lenth for folder names.
Distribution for 2x2 prefixes:
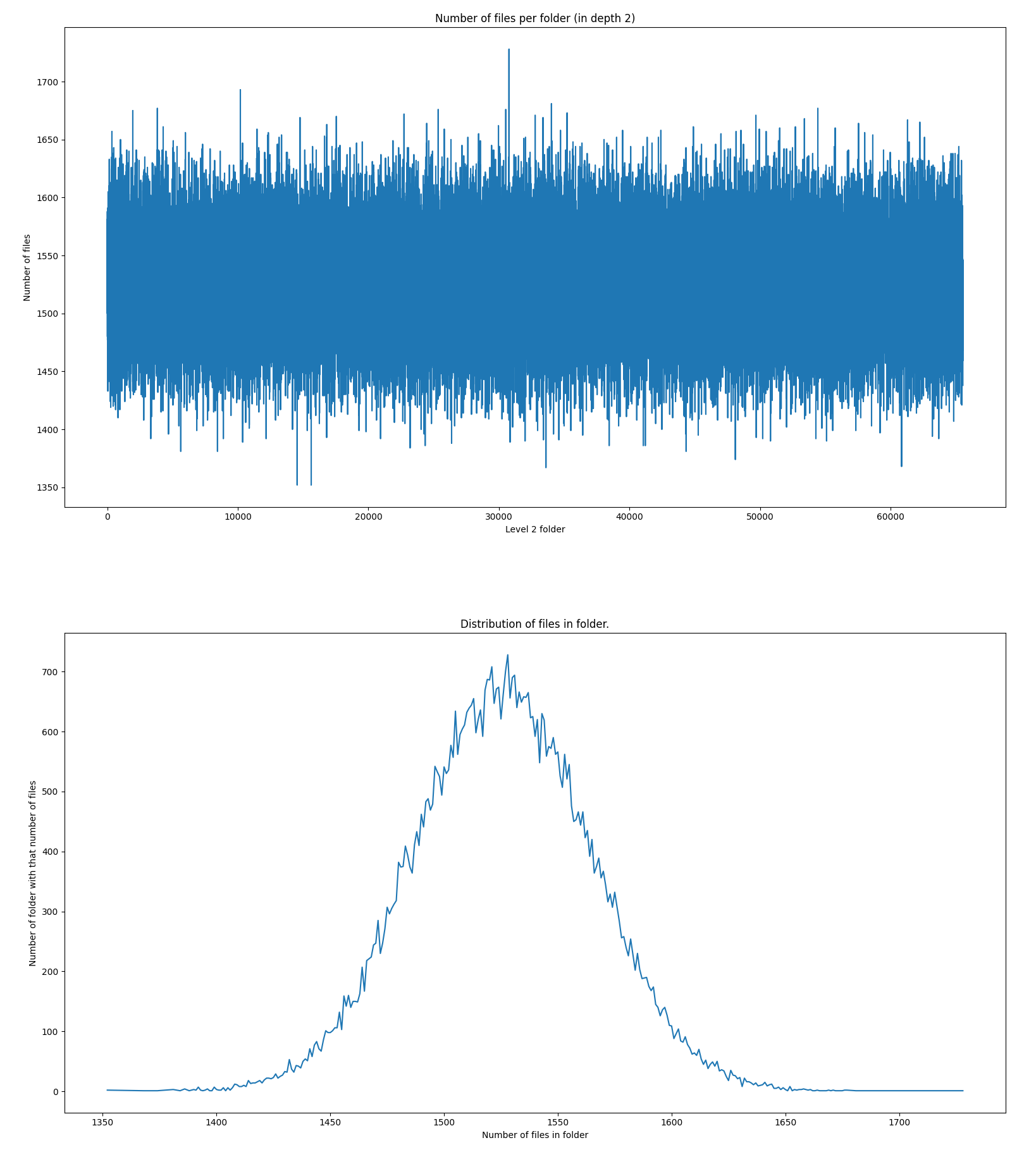
First thing is the dramatic decrease in depth 2 folder count. It went down from 16 million to just about 60 thousand. Number of files is between 1450 and 1600. If our goal was to have 1000 files we woulb be over budget. In theory we should have 100_000_000 / (256 * 256) = 1525. It looks like experiment is lines up pretty good with theory that md5 distriutes evenly.
Distribution for 1x1 prefixes:
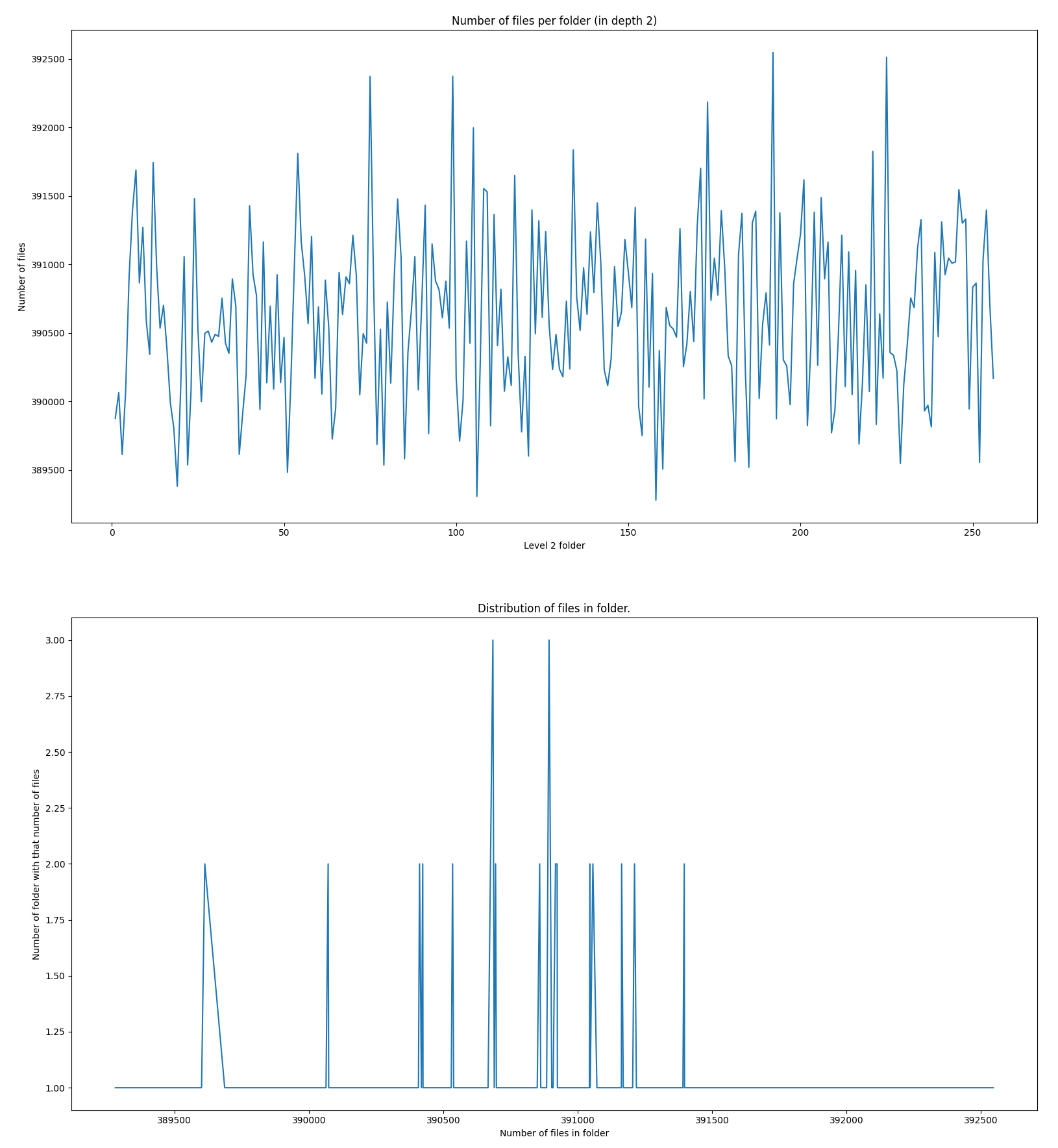
This graph start reminding something from chaos theory but let’s not search for meaning in shapes. Now we get only on 256 folders in depth 2 and about about 390_000 files per folder. This is totally not suitable for the usecase of not having more than 4k files per folder but it is good as a datapoint to compare with. This might not be usable in the form of 1x1 distribution but could be usable in 1x3. Which would give about 1500 files per folder and yet you would get 16 distinct blocks to distribute over 16 computers/disks.
It looks like for my usecase a 2x2 distribution pattern seems like more appropriate compared to other methods. Here is a list of some ways to distribute files and them amount of files per folder as a quick lookup. The format is like AxB where A is how much characters we take from start of the hash for names of folders in depth 1 and B is subsequent number of characters to take from hash for name of folders in depth 2.
0x0: 100000000
0x1: 6250000
0x2: 390625
0x3: 24414
1x0: 6250000
1x1: 390625
1x2: 24414
1x3: 1526
2x0: 390625
2x1: 24414
2x2: 1526
2x3: 95
3x0: 24414
3x1: 1526
3x2: 95
3x3: 6
It was a bit crazy and at the same time interesting dive into ways of how to distribute files. Now I got solid numbers to use for different usecases that I have and got a few scripts to play around for quick calculations. Initial my idea was to use different hashing algorithms as I though that md5 was too bad and didstribution of files should be imporoved. But experiments showed that it is totally fine to use for this task and there is no need to look for better alternatives.
The way to divide files described here is too simplistic but good enough for my projects. To get more fine grained access you could switch from using hex character to decimals or even go crazier and take first characters and convert them to real numbers. This will give access for a very tuned access to splitting files in more smarter ways.